
… a pu se demander la grande championne de ski Mikaela Shiffrin après avoir été copieusement insultée, parfois de manière ordurière, suite à sa déconvenue aux Jeux Olympiques de Beijing en 2022. Des amabilités comme « tu supportes pas la pression », « tu as ce que tu mérites », « idiote de blonde », « prends ta retraite » et d’autres moins polies lui ont été adressées sur Twitter et Instagram, par exemple, par de courageux anonymes, protégés par les insuffisances sécuritaires des réseaux sociaux. Si ce genre de remarques peut s’avérer décourageant pour une grande championne et une célébrité, que dire des jeunes adolescents, pour qui le phénomène du cyber harcèlement peut s’avérer plus dommageable, voire parfois léthal? Remonter à la source de ces commentaires n’est jamais très simple, et peut s’avérer très compliqué et parfois même impossible. Pourquoi donc?
Les télécommunications ont connu un essor proprement invraisemblable depuis la fin de la deuxième guerre mondiale jusqu’à nos jours. Plus encore que l’informatique, les moyens de communication sont passés en quelques décennies de la transmission limitée de la voix aux transmissions multimédia à très haut débit que chacun utilise quotidiennement et parfois de manière abusive.
Les analogies ne sont pas forcément pertinentes, mais je me souviens que, dans les années 1980, j’effectuais mes paiements mensuels en utilisant un modem à 9600 bit/seconde sur une ligne téléphonique standard, avec une bande passante de 3.1 kHz. Beaucoup d’utilisateurs n’avaient que des modems à 1200 ou 2400 bit/seconde. Par contraste, je fais toujours actuellement mes paiements mensuels en utilisant des moyens téléinformatiques, mais les débits sont compris en 40 et 150 Mbit/seconde, soit grosso modo cent mille fois supérieurs. J’ajoute que je réside dans une région (littoral neuchâtelois) où les débits proposés sont corrects, sans être vraiment pharamineux, et que même si j’en éprouvais le besoin, je ne pourrais pas parvenir à des débits comparables à ce qu’expérimentent certains de mes amis mieux situés (région lausannoise, par exemple). Essayons simplement d’imaginer un progrès similaire pour l’automobile ou l’aviation : même la science-fiction n’a pas osé une telle extrapolation. Par quel miracle en est-on arrivé là ? Les progrès en traitement du signal et en microélectronique, diront les ingénieurs; la motivation de bénéfices de plus en plus juteux, rétorqueront les cadors de l’informatique mobile…
Par contraste, malgré les performances de nos réseaux de télécommunications, il semble qu’il devienne de plus en plus difficile d’en garantir un usage adéquat : failles sécuritaires, pourriels, messages non sollicités, rançongiciels, mobbing se disputent joyeusement l’utilisation des réseaux en relative impunité, grâce à un anonymat largement soutenu par les protocoles de communication sous-jacents. Pourquoi est-il donc si difficile de savoir qui est réellement à l’origine d’une information dans le monde Internet ?
Pour envisager une réponse à cette question justifiée, il faut comprendre comment s’est développé Internet, comment il est organisé, et cela impose quelques notions théoriques et historiques qui sembleront indigestes à certains : je ne leur en voudrai pas s’ils m’abandonnent en cours de route, promis !
A l’époque où j’étudiais les télécommunications à l’EPFL, Internet n’était qu’un projet (qui se nommait ARPANET, initié à l’origine par les militaires de DARPA) mené par quelques universités américaines. En 1976 (j’étais alors assistant à l’EPFL), j’avais passé quelque temps à l’université d’été à Lannion dans les Côtes d’Armor (France), au CNET, où étaient donnés des cours avancés en téléinformatique (on faisait à l’époque la distinction entre les communications entre humains et entre ordinateurs). Nous avions eu droit à un cours assez exhaustif sur ARPANET, et sur les travaux avancés de l’INRIA (qui s’appelait encore IRIA) qui cherchait à formaliser les développements récents en téléinformatique. C’est à cette occasion que j’eus une première description de la modélisation d’un système de communications, et un aperçu du modèle OSI dont la formalisation définitive intervint deux ans plus tard. OSI est l’abréviation de « Open Systems Interconnection », et désigne un modèle qui permet de séparer les fonctionnalités dans un système de télécommunications en « couches » matérielles ou logicielles, chacune remplissant certaines fonctionnalités nécessaires à la communication, de telle manière que l’implémentation d’une couche quelconque puisse être échangée contre une autre implémentation sans que la fonctionnalité de l’ensemble en soit impactée. En pratique, cela permet à votre navigateur Internet favori d’accéder de manière transparente à un site par le biais de votre réseau WiFi domestique ou depuis le train en utilisant votre smartphone comme passerelle de communication. Pour le navigateur, il n’y a aucune différence visible. Pour l’utilisateur, seule une éventuelle dégradation de la vitesse pourra indiquer le changement de média de transmission. Parallèlement à la communauté scientifique européenne, les universités américaines développèrent aussi un modèle de communications en couches, mais beaucoup plus simple, à la manière pragmatique des nord-américains.
L’image ci-dessous a été empruntée au site GURU99, mais on peut aussi consulter la référence sur Wikipédia pour obtenir un descriptif un peu plus exhaustif du modèle. A gauche, on a représenté le modèle OSI tel que défini en Europe, à droite, une correspondance avec le modèle américain; dans le modèle américain, la couche la plus basse (Network Interface) est souvent appelée MAC (Media Access Control), la couche Network est plus connue sous le nom de IP (Internet Protocol), et la couche Transport sous le nom de TCP (Transport Control Protocol).
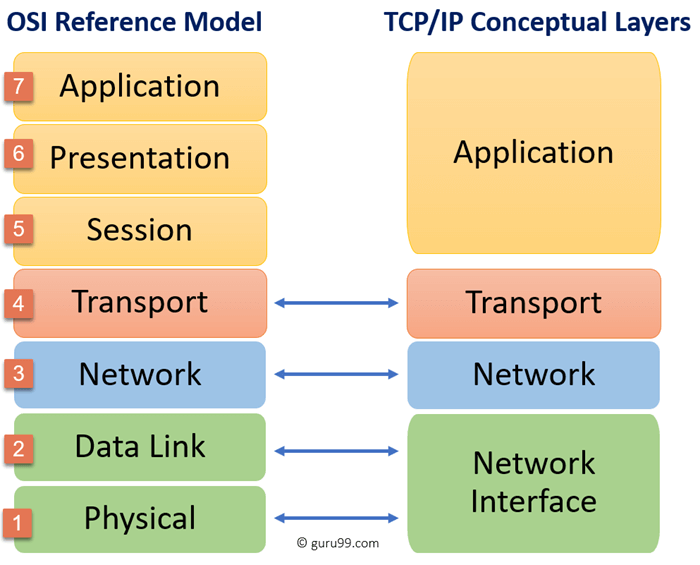
Pour utiliser une analogie grossière, le problème est assez similaire au processus qui permet l’achat d’une livre de pain chez votre boulanger.
Physical layer : Pour communiquer avec le boulanger, vous utilisez votre organe phonatoire, l’air et vos oreilles. C’est le support physique de la transmission : fil, ondes électromagnétiques, fibre optique, relais satellite, etc…
Data Link Layer : Vous formez des sons qui assemblés, composent des phonèmes et des mots que le boulanger sera en mesure d’interpréter. C’est la segmentation en unités de transmission faciles à gérer et à contrôler.
Network Layer : Il s’agit d’identifier un interlocuteur susceptible de vous vendre du pain et de s’assurer que c’est bien lui qui vous écoute et vous sert. C’est la détermination de la destination et d’un chemin menant à celle-ci.
Transport Layer : Les différents phonèmes que vous avez générés forment une ou plusieurs phrases qui ensemble forment un message; genre : « Bonjour, je voudrais une livre de pain ».
Session Layer : L’ensemble des phrases émises par un requérant et des réponses du destinataire (chacune correspondant au résultat d’une opération de la couche Transport) forment une transaction; par exemple, le dialogue suivant :
- Bonjour, je voudrais une livre de pain
- Bonjour, voici votre pain, cela fait 2 Euros
- Merci, voici 5 Euros
- Merci je vous rends 3 Euros
Quel que soit le point dans lequel on interrompt cet échange, il y a une perte pour l’un des interlocuteurs; soit le pain n’est pas remis, soit il n’est pas payé, ou alors la monnaie n’est pas rendue : la couche session permet de s’assurer que les quatre messages sont tous transmis et reçus correctement dans l’ordre voulu.
Presentation Layer : Le dialogue ci-dessus pourrait se dérouler entre un client ne parlant que le chinois et un boulanger francophone, une tierce personne jouant les interprètes de fortune, ou les interlocuteurs utilisant des signes suffisamment expressifs ; le contenu sémantique et le résultat ne devraient pas changer pour autant.
Application Layer : Si vous utilisez une carte de crédit, ou avez une ardoise chez le boulanger, il faudra vous authentifier, implicitement ou explicitement, avec une identité (pièce d’identité ou ID électronique), la reconnaissance du boulanger ou un mot de passe.
Chose intéressante, pour acheter une livre de pain, il n’est pas nécessaire de connaître l’identité des protagonistes, sauf si le moyen de paiement le requiert. Si le moyen de paiement est anonyme (monnaie), alors le processus complet peut rester anonyme. Ceci correspond à l’expérience habituelle chez un boulanger chez qui l’on n’est pas forcément connu.
Nous vivons actuellement dans une galaxie régie par le modèle américain (TCP-IP), et il semble bien que cette situation soit appelée à perdurer encore quelque temps. Ceci implique que les couches supérieures (Session, Presentation et Application) ne font l’objet d’aucune définition ni d’implémentation standardisée. Chaque application est libre d’implémenter les services correspondants à sa guise. Les deux modèles ne sont en réalité pas si différents qu’on pourrait le penser de prime abord; simplement, les européens ont voulu modéliser l’ensemble du problème, alors que les nord-américains se sont contentés du problème de l’acheminement de bout en bout des éléments d’information. On l’a vu dans la modélisation précédente, la notion d’identification n’est prévue qu’au niveau de l’application; il s’ensuit, puisque nous sommes dans le modèle nord-américain, que rien n’est prévu dans le protocole de communication pour l’identification des utilisateurs.
Les deux modèles sont axés sur le problème d’ingénierie que représente l’acheminement fiable et sûr de l’information d’un point A à un point B en passant par un réseau arbitrairement complexe de relais de communication et de vecteurs de transmission hétérogènes. Cette problématique d’acheminement est en principe entièrement résolue au niveau Transport (OSI niveau 4, ou protocole TCP dans le modèle TCP-IP) : ce qui vient au-dessus concerne les applications et les utilisateurs. Il est intéressant de remarquer que l’acheminement ne fait aucun cas de l’identité des utilisateurs, sinon par une référence abstraite qui désigne le terminal utilisé (adresse IP ou numéro de téléphone, par exemple). C’est simplement que l’ingénieur n’a aucun besoin de cette identité, le terminal lui suffit amplement; si on désire restreindre l’accès à certains utilisateurs, ce n’est pas, au vu de l’ingénieur, un problème de télécommunications, mais le problème du terminal lui-même. Cela paraît logique et pertinent, mais cela a des conséquences que nous n’avons pas encore fini de subir.
La principale conséquence est que le réseau permet l’anonymat, sans toutefois le garantir. Il est possible, avec un minimum de précautions, de transmettre de l’information de manière raisonnablement anonyme à des personnes que l’on ne connaît pas forcément, simplement en détectant l’adresse d’un terminal auquel ils sont raccordés. Cela permet de protéger l’identité des personnes qui désirent critiquer le gouvernement sans finir leurs jours dans un quelconque goulag en Mongolie Inférieure, et c’est probablement, à ce point de vue, une assez bonne chose. Mais cela peut aussi protéger l’identité de certains harceleurs, ou diffuseurs de fausses nouvelles. Cela permet aussi à un utilisateur pas trop malhabile d’usurper l’identité de quelqu’un d’autre. C’est aussi la porte ouverte à la diffusion de pourriels ou à l’organisation d’arnaques plus ou moins sophistiquées, comme l’arnaque nigériane, par exemple, qui rapporterait, selon diverses sources, des centaines de millions de dollars annuellement aux utilisateurs malveillants (en Côte d’Ivoire, on les appelle des brouteurs).
Le réseau n’imposant pas l’identification des usagers, ce sont les applications qui doivent s’en charger; mais ce n’est pas simple : comment garantir que la personne qui ouvre un compte sur un site quelconque est bien celle qu’elle prétend être ? Ouvrir un faux compte sur Facebook n’est pas excessivement complexe et constitue un problème assez sérieux pour les opérateurs de sites de ce genre. Il en va de même pour le problème assez voisin qui est de vérifier que l’utilisateur d’une information le fait de bonne foi, et non pour nuire à la société : le CEO de META, Mark Zuckerberg, en sait quelque chose après le procès retentissant qu’il a perdu pour avoir permis l’exploitation de données par Cambridge Analytica. Exploitation qui a permis accessoirement à Donald Trump d’accéder au pouvoir, en tous cas, nombreux sont les experts qui le pensent. Ces mêmes mécanismes sont également utilisés pour la diffusion de fake news, qui foisonnent régulièrement en période électorale afin d’influer sur les électeurs en discréditant un candidat paraissant indésirable à un groupe industriel ou à un état malveillant. Si on ajoute à toutes ces opportunités de nuire impunément la gratuité des services de base (dont j’ai déjà parlé précédemment), Internet est un réel paradis pour les utilisateurs malveillants.
Il n’est pas certain qu’un accès au réseau authentifié permette d’éviter tous ces inconvénients; mais la fraude en serait à tout le moins rendue beaucoup plus complexe. Et certaines activités seraient du coup rendues plus sûres et plus faciles à réaliser.
Mais quels eussent été les prérequis, dans les années 1980, pour l’intégration de l’identité de la source dans les protocoles de communication ? Cela eût-il été possible ?
La réponse n’est pas forcément évidente à donner; il n’est d’ailleurs même pas certain que cela soit possible de nos jours. En prérequis, il est nécessaire de disposer d’une identité électronique. En 1975, cette exigence représentait techniquement une gageure; sa réalisation eût probablement retardé le déploiement d’Internet de plusieurs années : ni les connaissances théoriques (le chiffrement RSA, par exemple, date de 1983), ni les implémentations mathématiques, ni la puissance des processeurs n’étaient disponibles à l’époque. Actuellement, cette exigence serait vraisemblablement difficile à faire accepter aux utilisateurs, alors même qu’il semble compliqué de simplement définir une identité électronique fiable et ayant un caractère universel, même si techniquement, cela ne représente plus un problème insurmontable. De plus, comme il s’agit d’un prérequis global au niveau de la planète, on peut être raisonnablement certain que l’unanimité ne serait pas aisée à réaliser, et s’attendre à ce que nombre d’états s’opposent à une telle exigence.
Plus préoccupant, soumettre toute unité de communication à une identification électronique coûte très cher. Implémenter ceci au niveau IP (transmission de paquets élémentaires) implique une identification de l’utilisateur pour chaque paquet de données transmis, soit, techniquement, une redondance et un surcroît de traitement immense : il faut savoir que cette opération entraîne, dans l’état actuel de la technique, une algorithmique non triviale, impliquant de la cryptographie complexe. Implémenter l’identification au niveau 4 (Transport) serait certes moins lourd, mais outre le fait que nombre d’applications n’utilisent pas le niveau transport, il est des applications qui ne nécessitent pas d’identification, comme par exemple la consultation d’un horaire de chemin de fer, ou la lecture des prévisions du temps, voire encore la consultation de cet article. A quoi bon imposer une identification dans ces cas particuliers ?
On en conclut que le modèle OSI que nous avons très succinctement introduit plus haut n’est pas injustifié : l’identification des utilisateurs est un problème lié à l’application, pas à la communication. Nous n’avons en revanche pas adopté le modèle OSI, mais sa contrepartie américaine simplifiée. Il n’existe donc pas de « standard », ni au niveau de la définition, ni au niveau de l’implémentation, pour les trois couches supérieures du modèle, donc pour les services de Session, de Présentation et d’Application. Sans couche Application, pas de standard pour l’identification des utilisateurs, et c’est à chaque application d’implémenter sa propre cuisine en fonction de ses besoins. Ainsi, les banques en Suisse ont adopté pour la plupart un schéma basé sur un intelliphone qui sert aussi de dispositif d’acquisition pour les codes QR de facturation; les assurances, de leur côté ont opté pour un système basé sur un code dynamique, un TAN (Transaction Authentication Number) transmis par intelliphone. Mais ces deux acteurs n’ont qu’à identifier des utilisateurs connus, alors qu’un acteur comme Facebook doit aussi définir de nouveaux utilisateurs, et c’est le plus souvent à ce niveau que les fraudes apparaissent.
Pourquoi le modèle nord-américain, basé sur TCP-IP, s’est-il imposé ? Tout simplement parce qu’il avait l’avantage d’exister, et d’être déjà déployé au niveau de certains pays, en particulier aux Etats-Unis et en Grande-Bretagne, et une entreprise comme Cisco Systems avait pu déjà inonder certaines entreprises de routeurs IP bon marché; par contraste, les implémentations européennes basées sur le mode de transfert asynchrone ATM étaient loin de connaître un tel développement. En 1995, les fabricants d’ordinateurs portables avaient besoin d’un standard mécanique pour connecter les « laptops » au réseau informatique : ils ne désiraient pas devoir introduire des cartes réseau interchangeables, coûteuses et aux connecteurs fragiles. La norme de connecteurs RJ45 convenait parfaitement aux constructeurs comme HP, COMPAQ, Apple et autres qui favorisèrent en conséquence l’implantation des protocoles de la famille IP dans les administrations et les entreprises. Que ce soit pour des raisons économiques, ou par manque de clairvoyance, ou encore pour des raisons moins avouables, les politiciens européens ne tentèrent pas, à l’époque, d’influencer ces choix, ce qui provoqua, à terme, la ruine des télécommunications en Europe (Siemens, Ericsson, et surtout Nokia).
Refaire l’histoire n’a jamais amené grand-chose de positif, mais Internet eût-il été « meilleur » si un modèle à 7 couches fonctionnelles avait été introduit et implémenté ?
Une couche Session, au-dessus de TCP-IP, permettrait de garantir l’intégrité de toute transaction; ceci permettrait de remplacer, par exemple, les fameux cookies qui nous empoisonnent l’existence lors de la consultation de sites web, et accessoirement permettent un traçage de nos activités parfois à la limite du raisonnable.
Une couche Presentation, permettrait de normaliser la présentation de l’information à destination de personnes de langues différentes, ou présentant une déficience physique (malvoyance, incapacité d’utilisation d’un clavier, etc…)
Et la fameuse couche applicative permettrait, entre autres services, d’implémenter la notion d’identification, de manière unique et sécurisée. Dans le cas idéal, on pourrait même renoncer aux mots de passe, dans la mesure où une identité électronique universelle et fiable est disponible. Oui, bon : là, on est un peu dans le domaine de la science-fiction, car le problème n’est plus technique, mais politique et économique, voire un problème de société.
Malheureusement, il me semble peu probable qu’une telle évolution ait lieu dans un proche futur; on continuera encore longtemps à douter de l’identité réelle de l’expéditeur de ce courriel qui vous promet dix millions d’euros simplement en cliquant sur un lien proposé dans le corps du texte. Si des lois peuvent à court terme avoir un effet dissuasif sur certains, les vrais criminels continueront de sévir, certains de leur impunité.
Qui c’est ? C’est l’plombier, bien sûr, mais à l’instar du célèbre sketch de Fernand Raynaud, si Mikaela Shiffrin veut savoir qui est vraiment le plombier derrière la porte, elle va au-devant d’une longue procédure juridique et d’une enquête compliquée, sans garantie de succès.